-
Baby names from across the globe
I was looking through this site and found several draft articles I wrote nearly a decade ago that I never published. This one was a list of links to official baby name data from governments around the globe. Most of the links were outdated, so I updated them. I also added a few countries. Of…
-
How the NYPL confirmed 480,000 books were in the public domain

The New York Public Library (NYPL) has been engaged in an impressive project over the past year to figure out which books published between the years 1923 and 1964 are no longer protected by copyright (TL;DR 480,000 books). People interested in sort of thing have long known that books published before 1923 were out of…
-
Name Templates

This is the second genealogy standards proposal I am submitting to the FHISO Call For Papers. This current document was started back in August after submitting my last proposal (Asynchronous Collaboration), but life intervened and I didn’t finish the last 10% of the document until today. The basic premise of this proposal is that names…
-
Asynchronous Collaboration: A Proposal

As part of the FHSIO Call for Papers, I am submitting the following proposal as my contribution to furthering genealogy. The full proposal is available in a downloadable PDF at the end of this post, but let me give a brief outline here, which I’ll excerpt from the introduction: In addition to these benefits, the…
-
Popularity of girls names in the US
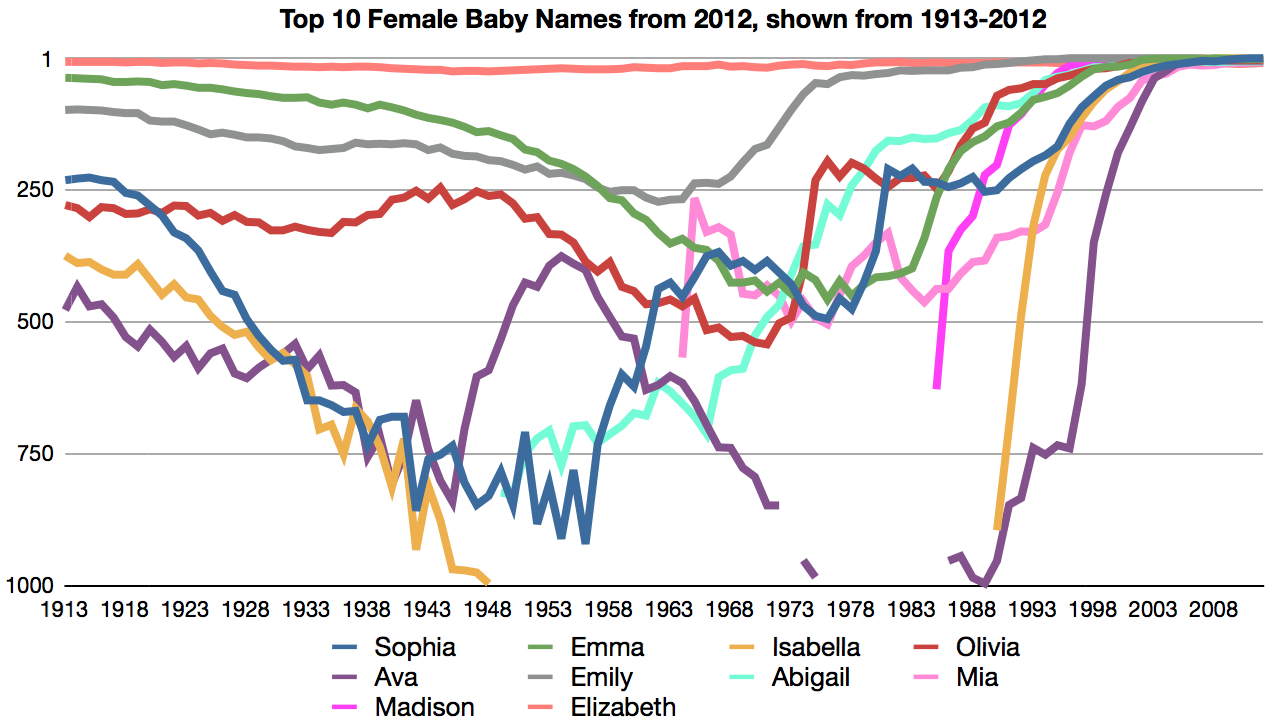
When putting together a dictionary of names, it is useful to know the origin of names, as well as their relative popularity. No book (in print anyways) can have an unlimited number of names, and thus popularity can be useful in determining whether or not a particular name should be included. One very useful resource…
-
Digitizing print books for research and corpus integration

One of the bigests tasks in planning the dictionary I want to make is just collecting and organizing the data I’m basing my definitions on, and putting them into some kind of searchable interface. Part of this is building a corpus, and part is organizing other sources and references that can help me. Some of…
-
Google Fonts take off from the web
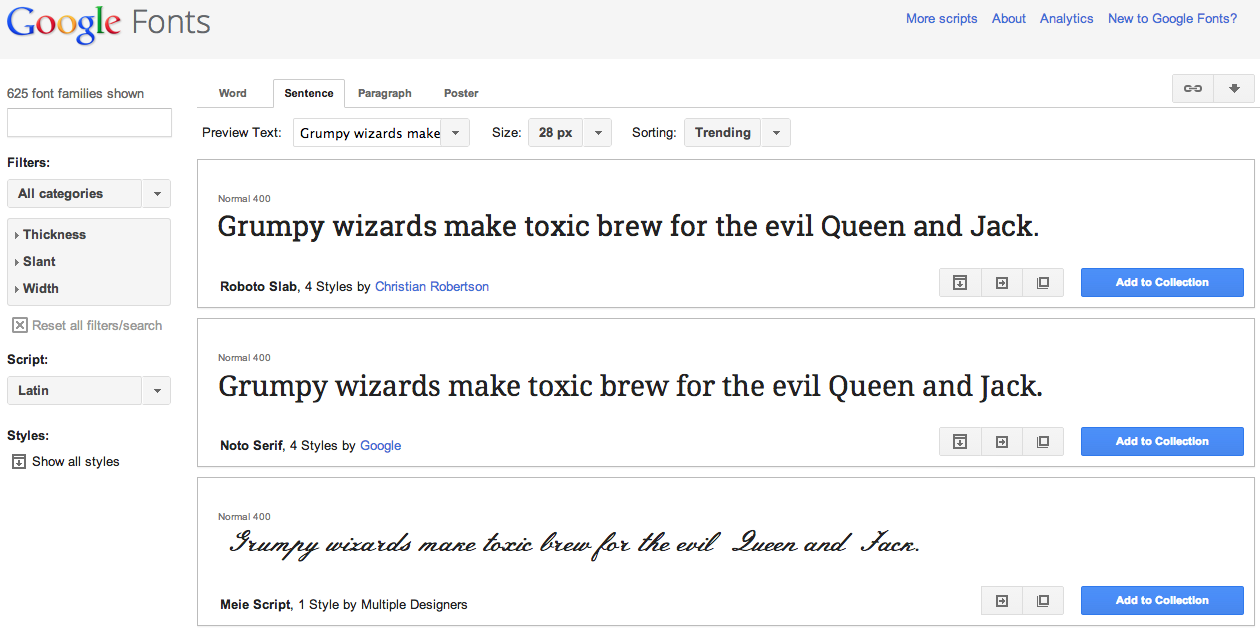
Web design has come a long way since the days of black text in a single font on a white background. Over the years typography on the web has jumped ahead, first to what were called ‘web safe’ fonts, which were a group of 18 fonts that were found on both Mac and Windows machines,…
-
Combining interests in Lexicography, Genealogy and Technology
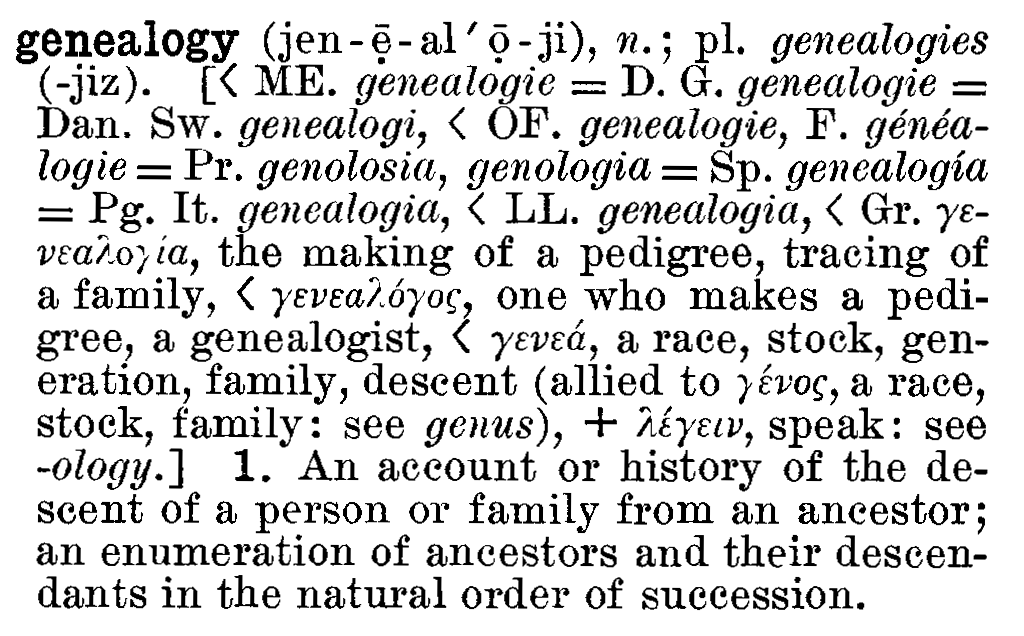
I’ve been blogging about genealogy for a few years on my other blog, Blood and Frogs: Jewish Genealogy and More. I’ve found that when I go off-topic too much some readers sometimes get annoyed, so I’m starting this new blog as a way to document my combined interest in the fields of Lexicography, Genealogy and…