One of the bigests tasks in planning the dictionary I want to make is just collecting and organizing the data I’m basing my definitions on, and putting them into some kind of searchable interface. Part of this is building a corpus, and part is organizing other sources and references that can help me. Some of the data sources I have are only available as print books, but in order to integrate them into my overall workflow, I’ve started to scan many of the books I am using so I can search them on my computer. One book, for example, is a book in Hebrew on Jewish names. The main steps in digitizing the book include:
- Scanning the book
- Splitting the scanned pages into two pages (since each scan covers two pages)
- Running OCR on the book to make it searchable
So let’s take a look at how I go about these steps.
Scanning
I start by scanning the book. I have a Brother mutli-function scanner/printer which is particularly good because it offers full A3/Tabloid scanning (i.e. I can scan a full spread of two pages of a letter-size book). The scanner also has wireless networking which is nice, although in this case where I’m scanning many pages it’s better to use a USB cable as it is faster, and the scanning time is reduced. I use VueScan software to do all my scan work. It’s an amazing piece of software that I’ve used for many years, and works with almost every scanner in existence. I actually have three scanners, all from different manufacturers, and they all work flawlessly with VueScan. VueScan lets you scan multiple pages into a single PDF, so I use that option to create a single PDF of the entire book.
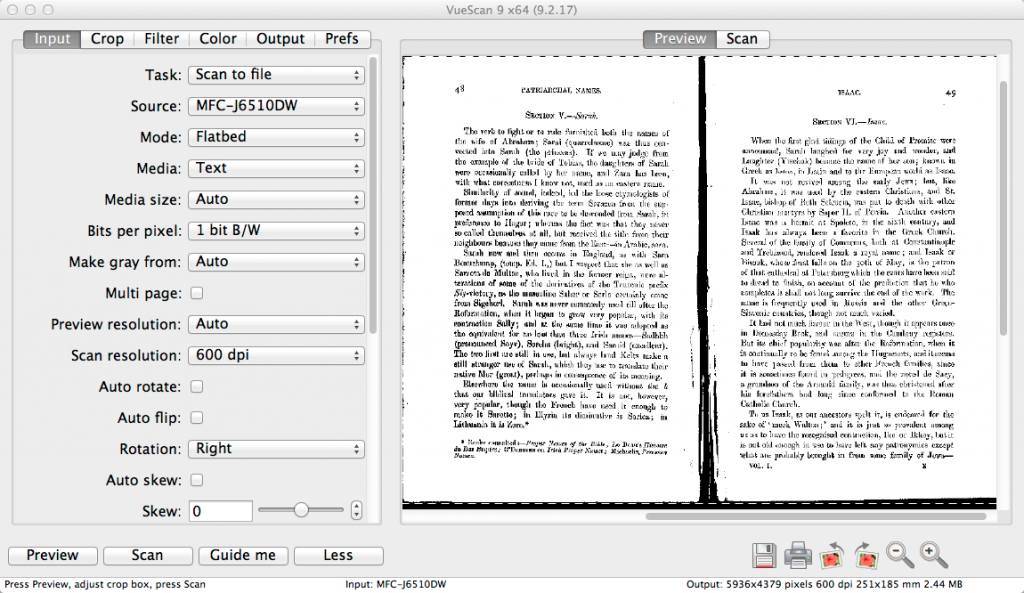
In general, scanning a book with the purpose of doing OCR needs to be done at no less than 300dpi, and would be better at 600dpi. The more resolution, the more information the OCR software has to interpret which letters it is seeing. In the case of Acrobat Pro at least, you can’t use a file that is scanner at more the 600dpi – if you do, it will first downsample the file to 600dpi, and then apply the OCR.
Splitting
This next step is one I’m hoping to find a better solution for, but this is still a pretty neat way to solve this problem. The problem is that when scanning a book you usually scan two pages at once. So how do you split the pages so your document only shows one page at a time? If you’re planning on being able to load your book on a iPad or other tablet, then this step is very important.
What I discovered is a program called Briss that lets you crop PDF pages into multiple pages. Yes, that’s BRISS as in the Jewish circumcision ceremony (snip snip). What Briss does which is pretty neat is that it takes a look at all the pages in your PDF, and combines them into one overlaid image that shows you where the boundaries of all your pages are – in other words it allows you to crop the pages without losing any text just because one page was slightly shifted from the other pages. Here’s what that looks like:

Once you can see all the pages together, you just draw boxes over the pages so they will crop in the right places. See here:

The original idea for Briss was actually to allow people to scan books for digital readers, and besides spitting the pages, also cropping out the extra white space (i.e. the margins) which are not necessary on an e-reader. In most cases you would put the first crop box on the left, and the second on the right. In this case, as the book is in Hebrew and Hebrew is read from right-to-left, the crop boxes are reversed. The next step is to simply output a cropped file, which creates a new PDF with the cropped pages in the correct order (with double the number of pages).
There are a few problems with Briss. First, I’ve tried to crop larger files (my scanner can scan full tabloid) and it has not loaded the files properly. I’m not sure yet if it’s a problem with size, or with resolution. The other problem is that there doesn’t seem to be a way to insure the cropped pages are all the same size. It’s weird when every other page is slightly different in size. There are some other programs with try to address this problem, such as ScanTailor on Windows, but I haven’t found anything that splits pages without any hiccups. I hope there will be better software for this in the future (or that Briss will improve).
Making the document searchable
So now the book is scanned, and the pages are split up so it looks like a normal digital book. The only problem is that the PDF is essentially just a series of images. There is no searchable text in the document. What we need now is OCR (Optical Character Recognition) software to generate text from the images of the words. VueScan actually has built-in OCR software, although Hebrew is not one of its currently supported languages (although I’ve asked them about that, and they’ve said they will look into it). OCR software for English is relatively easy to find. There are many options, ranging from essentially free to more expensive options with more advanced features. One of the more advanced features that one can pay for is the ability to process more than one language at once. Some of the documents I’m looking at can have some combination of English, Hebrew, Russian, Polish and Yiddish. Finding a program that can do all of that at once is probably not realistic.
Most OCR programs will ask you what the ‘primary’ language is in the document. Part of the reason for this is that the OCR software can use dictionaries to improve its accuracy, but it needs to know which dictionary to use in order to do that…
Hebrew is not one of the most supported languages in OCR software (it adds to the complexity by being read right-to-left like Arabic). Of the major OCR software companies, even fewer have full products on the Mac. In something all too typical, ABBYY which makes the well-regarded FineReader OCR software, provides a version for the Mac which is based on version 8 of their software, which debuted in 2005. The current version, 11, which is much improved and supports many more languages including Hebrew, is not available on the Mac. Am I wrong to not to want to pay for software that is 8 years out of date?
Luckily for a document that is solely Hebrew, there are some options. Adobe Acrobat Pro offers its own OCR software (apparently based on the Readiris engine), which does a reasonable job.
Acrobat also offers a feature that they call ‘Optimize PDF’ which does OCR, then compresses the images so the file is much smaller. Once you have the text recognized, there is no good reason to keep a very high resolution and uncompressed version of the pages in the document. It also does something else – it analyzes each page and rotates them if it thinks the page is not straight. This is a common problem when scanning books, since the book doesn’t always lay perfectly flat. The result now is fully-searchable document that is formatted to be viewable on both a computer and on a tablet if you want to be able to take the document with you.
Next Steps
Some OCR software can detect double-page spreads and crop them automatically, which would be nice as it would eliminate the need for using a second program like Briss. I’d like to see if programs like Readiris 14 Pro can do that, and whether they support multiple languages (English, Hebrew, Yiddish, Polish, Russian, etc.) and multiple character sets (Latin, Hebrew, Cyrillic, etc.). Unfortunately, Readiris 14 Pro only supports scanning 50 pages at a time, not something conducive to scanning books. It seems an odd restriction for something labelled ‘Pro’. To scan unlimited pages you need to buy their $599 Corporate version, not something I’m planning to do.
In short there isn’t an ideal solution to the problem of digitizing books for research and corpus inclusion. I’ll continue to look at options available, and post about solutions I find that help streamline the process. If you scan books and run OCR on them, what solution have you come up with?